ASCII кодиране. ASCII таблица за кодиране
под информация за кодиране в компютъра се разбира процесът на неговото преобразуване във форма, която дава възможност да се организира по-удобен трансфер, съхранение или автоматична обработка на тези данни. За тази цел се използват различни таблици. ASCII кодирането е първата система, разработена в Съединените щати за работа с текст на английски език, който впоследствие се разпространява по целия свят. Неговото описание, характеристики, свойства и по-нататъшна употреба на изделието са представени по-долу.
Показване и съхранение на информация в компютъра
Символите на компютърен монитор или мобилна цифрова притурка се формират въз основа на множества векторни форми на различни знаци и кодове, позволяващи да се намери сред тях характер, който трябва да се вмъкне на правилното място. Това е поредица от битове. По този начин всеки символ трябва еднозначно да съответства на набор от нули и такива, които стоят в определен, уникален ред.
Как започна всичко
Исторически, първите компютри бяха англоговорящи. За да се кодира символната информация в тях, достатъчно е да се използват само 7 бита памет, докато за тази цел се разпределя 1 байт, състоящ се от 8 бита. Броят на знаците, разбрани от компютъра в този случай, е 128. Тези символи включват английската азбука с нейните пунктуационни знаци, цифри и някои специални знаци. Английското 7-битово кодиране със съответната таблица (кодова страница), разработено през 1963 г., се нарича American Standard Code for Information Interchange. Обикновено за нейното обозначение е използвано и все още се използва съкращението „ASCII кодиране“.
Преход към многоезичен
С течение на времето компютрите започнаха да се използват широко в неанглоезични страни. В това отношение е необходимо кодиране, което позволява използването на национални езици. Беше решено да не се изобретява колелото и да се вземе ASCII като основа. Таблицата за кодиране в новото издание значително се разширява. Използването на 8-ми бит позволи да се преведат 256 символа на компютърен език.
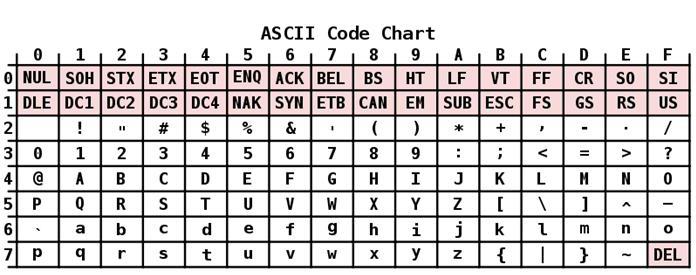
описание
ASCII кодирането има таблица, която е разделена на 2 части. Общоприетият международен стандарт се счита само за първата му половина. Тя включва:
- Символи с поредни номера от 0 до 31, кодирани от последователности от 00000000 до 00011111. Те са запазени за контролни знаци, които контролират процеса на показване на текст на екрана или принтера, бипкане и т.н.
- Символите с NN в таблицата от 32 до 127, кодирани от последователности от 00100000 до 01111111 представляват стандартната част на таблицата. Те включват интервал (N 32), латински букви (малки и големи букви), десетцифрени числа от 0 до 9, препинателни знаци, скоби от различен тип и други символи.
- Символи с поредни номера от 128 до 255, кодирани от последователности от 10 000 000 до 11 000. Те включват букви от национални азбуки, различни от латински. Тази алтернативна част на таблицата е ASCII кодирането, използвано за конвертиране на руски символи в компютърна форма.
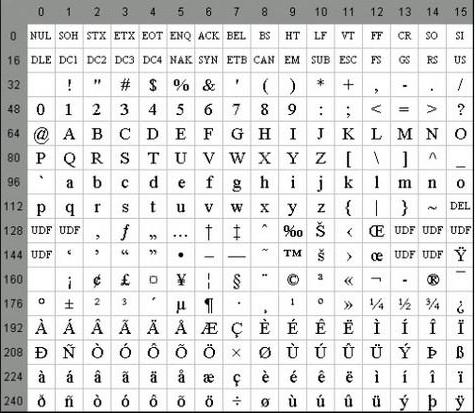
Някои имоти
Специфичните характеристики на ASCII кодирането са разликата между буквите “A” - “Z” на долния и горния регистър само с един бит. Това обстоятелство значително опростява преобразуването на регистъра, както и неговата проверка за принадлежност към даден диапазон от стойности. В допълнение, всички букви в системата за кодиране ASCII са представени със собствени серийни номера в азбуката, които са написани с 5 цифри в двоичната система с числа, пред които за малки букви е 011 2 , а горната е 010 2 .
Сред характеристиките на кодирането ASCII може да се брои и представянето на 10 цифри - "0" - "9". Във втората цифрова система те започват с 00112 и завършват с 2 числа. По този начин, 0101 2 е еквивалентно на десетично число от пет, така че символът "5" се пише като 0011 01012. Въз основа на горното можете лесно да конвертирате двоично-десетични числа в ASCII низ чрез добавяне на битовата последователност 00112 към всяка клетка отляво.

"Unicode"
Както знаете, за да се показват текстове на езиците на групата от Югоизточна Азия, са необходими хиляди знаци. Такъв брой от тях не е описан по никакъв начин в един байт информация, затова дори разширени версии на ASCII вече не могат да отговарят на нарастващите нужди на потребителите от различни страни.
Така стана необходимо да се създаде универсално текстово кодиране, чието развитие, в сътрудничество с много лидери на глобалната ИТ индустрия, беше поето от консорциума на Юникод. Нейните специалисти създадоха системата UTF 32. В нея бяха разпределени 32 бита за кодиране на 1 символ, който съставлява 4 байта информация. Основният недостатък е рязкото увеличаване на необходимата памет в 4 пъти, което доведе до много проблеми.
В същото време за повечето страни с официални езици, принадлежащи към индоевропейската група, броят на знаците, равен на 2 32, е повече от излишен.
В резултат на по-нататъшната работа на специалисти от консорциума Unicode се появи кодировката UTF-16. Тя се превърна в опция за конвертиране на символна информация, която подреждаше както за количеството на необходимата памет, така и за броя на кодираните символи. Ето защо UTF-16 е възприет по подразбиране и изисква 2 байта да бъдат запазени за един символ.
Дори тази доста напреднала и успешна версия на Unicode имаше някои недостатъци и след преминаване от разширена версия на ASCII към UTF-16, тя удвои теглото на документа.
В тази връзка беше решено да се използва кодирането с променлива дължина UTF-8. В този случай всеки символ в изходния текст се кодира в последователност от 1 до 6 байта по дължина.

Свържете се с американския стандартен код за обмен на информация
Всички знаци латиница в UTF-8 променлива дължина, кодирана в 1 байт, както в ASCII кодиращата система.
Специална функция на UTF-8 е, че в случай на текст на латиница, без да се използват други знаци, дори програми, които не разбират Unicode, ще продължат да позволяват четенето му. С други думи, основната част от кодирането на ASCII текст се прехвърля просто към новата променлива дължина на UTF. Кирилиците в UTF-8 заемат 2 байта, а например грузински - 3 байта. Чрез създаването на UTF-16 и 8, основният проблем при създаването на едно кодово пространство в шрифтовете беше решен. Оттогава производителите на шрифтове трябва само да запълнят таблицата с векторни форми на текстови символи на базата на техните нужди.
В различни операционни системи предпочитание се дава на различни кодировки. За да могат да четат и редактират текстове, написани в различно кодиране, се използват руски програми за преобразуване на текст. Някои текстови редактори съдържат вградени транскодери и ви позволяват да четете текст независимо от кодирането.

Сега знаете колко знака са в ASCII и как и защо е бил разработен. Разбира се, днес стандартът Unicode е станал най-разпространеният в света. Въпреки това не трябва да забравяме, че той е създаден на базата на ASCII, така че трябва да оценявате приноса на разработчиците му в областта на информационните технологии.