Файлове:
Формално, файлът съдържа съдържание на PHP конструкция, подобно на файла, но поставя прочетеното съдържание в низ, а не в масив от низове, и ви позволява да укажете отместване във файла, от който да започнете да четете.
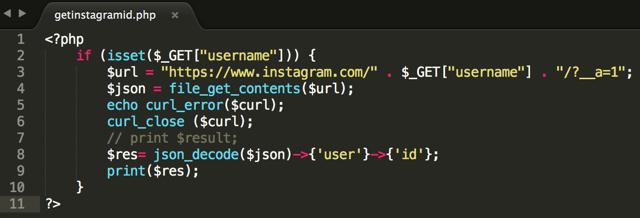
Редовното четене чрез fopen / fgets / fclose става по-малко приложимо. По-удобно е да се прочете съдържанието на целия файл или страницата на сайта и след това да се извършат необходимите операции с него. Конструкцията на PHP файла ви позволява да създадете по-ефективни и ефективни алгоритми. обработка на информация.
Синтаксис и пример за използване
синтаксис:

Тук $ filename е името на файла или URL на страницата, $ use_include_path ви позволява да търсите файла в path include, $ context е ресурсът, създаден от конструкцията stream_context_create (), $ offset е компенсирането за четене, $ maxlen е максималното количество данни, които трябва да се четат ,
Обикновено се използва по-просто PHP съдържание:
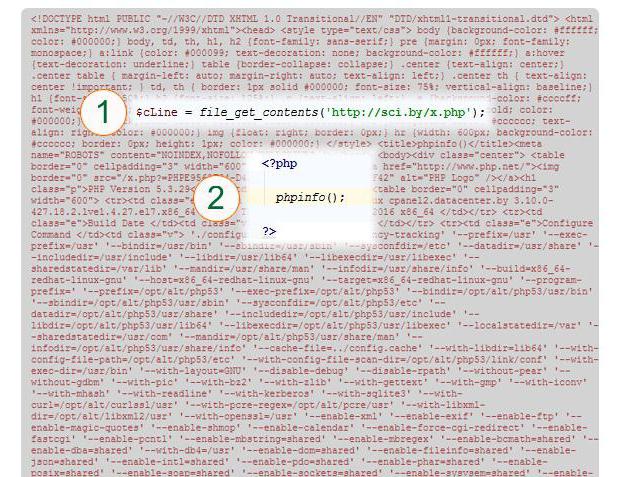 В този пример съдържанието на страницата се чете в променливата $ cLine (1). Посочен е посоченият URL адрес. Всъщност, страница (2) е представена от PHP phpinfo () конструкт, т.е. не е текст от три реда, който се чете, а резултатът от изпълнението на тази функция.
В този пример съдържанието на страницата се чете в променливата $ cLine (1). Посочен е посоченият URL адрес. Всъщност, страница (2) е представена от PHP phpinfo () конструкт, т.е. не е текст от три реда, който се чете, а резултатът от изпълнението на тази функция.
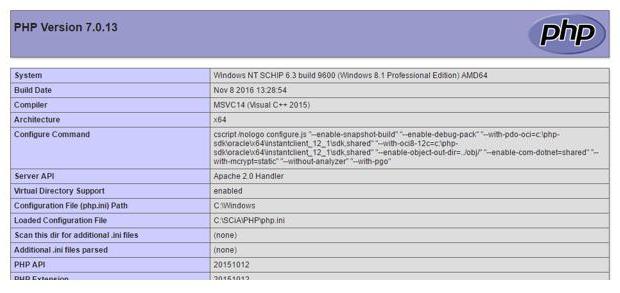
Както можете да видите, резултатът е пълноценна страница, докато PHP файлът съдържа конструкт на (http ...) прочете и написа вътрешното съдържание на тази страница в променливата $ cLine.
Контекстни опции и опции
Трябва да се има предвид, че използването на параметъра $ context отваря големи възможности.

При нормална практика използването на всички параметри, с изключение на $ filename, не е популярно правило. Въпреки това стойността, създадена от конструкцията stream_context_create () и използвана като параметър $ context ви позволява да пишете доста сложни алгоритми за получаване на необходимата информация.
Различни файлови системи, обработващи потоци (wrappers) изискват различни параметри и опции за описване на контекста. Тя може да бъде създадена чрез конструкциите stream_context_create (stream_context_set_option, stream_context_set_params).
Обработка на масови страници
Вместо специфичен URL адрес Параметърът $ filename може да бъде представен с име на променлива. Това дава възможност да се анализира съдържанието на сайтовете в автоматичен програмируем режим, да се разпознават имената на страниците, да се определят връзките, да се извлече необходимата информация.
Можете да създадете свой собствен анализатор на сайта, търсачка и да напишете програми за обработка на разпределена информация. Задачата е подходяща, интересна и практична.
Четене на текстови файлове
Няма проблеми, кой файл да се чете. В следващата сложна версия конструкцията на файла get content php е пример за това, че файлът "Word" може да се чете без проблеми:

Тук е сложен документ, който се използва за тестване на библиотеката PHPOffice / PHPWord. Файлът MS Word (* .docx), както знаете, е zip-архив, в който има информация за Open XML стандарта .
По правило файловете с документи са доста големи и сложни, но PHP файлът съдържа конструкт, който се справя с четенето им без затруднения. Спецификата на този конкретен пример се крие във факта, че обработката на документ, използвайки чисто PHPOffice / PHPWord библиотека означава, че не осигурява необходимите възможности и просто е невъзможно да се чете последователно.
В този документ всички негови елементи (думи, параграфи, формули, картини, правописни елементи) са описани от поредица от тагове, някои от които могат да бъдат представени чрез последователност от обекти, вмъкнати един в друг.
Ако вземете пример за документ (* .docx) с таблици, ситуацията изобщо не може да бъде решена с последователната обработка на даден файл. Тя изисква най-малко два преминавания през тялото на документа, ако не отиде по-специално, например, когато таблиците гнездят един в друг.
Кодиране и проблеми със специални знаци
Ако четенето на сложни файлове не причинява проблеми, тогава се срещат проблеми при работа с прости файлове. Първоначално тя трябва да се възприема като аксиома: PHP чете коректно съдържанието на файла. Дори и да не използвате определени параметри, най-простият вариант на неговото приложение винаги ще работи както трябва.
Трудностите се дължат на ъгловите скоби и кодирането на файловете. Необходимо е да се разграничи работата в алгоритъма от показване на резултата в прозореца на браузъра. На снимката с примера на файла Word, редът (1) - $ cLine = scChangeLTGT ($ cLine) - извиква функцията за преобразуване на двойка ъглови скоби в специални знаци “<” и “>”, в противен случай само четеният файл не винаги може да бъде показан в прозореца на браузъра. Как да напишем тази функция не е важно, но е важно да не забравяме, че прочетената информация може да съдържа XML и HTML тагове и това изисква специално внимание.
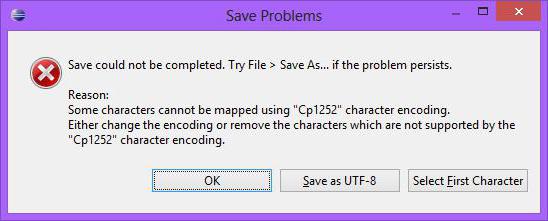
Следващата точка: кодиране на файлове. Не винаги един прост текстов файл не създава проблеми. Ако текстовата информация се чете, наличието на руски букви може да създаде някои трудности (2).
$ cLine = iconv ('UTF-8', 'CP1251', $ cLine). В този контекст, използването на функцията iconv () с правилната посока на преобразуване е релевантно не само по отношение на PHP файл "съдържанието http://" за четене на страницата на сайта, но и когато се чете обикновен локален файл.
Ако резултатът от четенето е "невидим", първото нещо е да проверите кодирането на знаците.