Unicode безплатна таблица със знаци
Unicode е международен стандарт за кодиране на знаци, който ви позволява да показвате текстове равномерно на всеки компютър в света, независимо от езика на системата, използван в него.
Основите
За да разберем защо е необходима Unicode таблица със символи, нека първо разгледаме механизма за показване на текст на екрана на монитора. Компютърът, както знаем, обработва цялата информация в дигитална форма и трябва да бъде показана в графична форма за правилно възприемане от човек. Следователно, за да можем да четем този текст, трябва да разрешим поне два проблема:
- Кодирайте печатаемите знаци в цифрова форма.
- Осигурете на операционната система възможността да съвпада с цифровата форма с векторни символи, с други думи, намерете правилните букви.
Първи кодировки
Предшественикът на всички кодировки се счита за американски ASCII. Той описва латинската азбука, използвана на английски език препинателни знаци и Арабски цифри. Именно използваните в него 128 символа станаха основа за по-нататъшно развитие - дори и съвременната таблица на Unicode символи ги използва. Оттогава буквите от латинската азбука заемат първата позиция във всяко кодиране.

Като цяло, ASCII позволи да се запазят 256 символа, но тъй като първите 128 бяха в латиница, останалите 128 започнаха да се използват по целия свят за създаване на национални стандарти. Например в Русия на негова база са създадени CP866 и KOI8-R. Такива вариации се наричат разширени версии на ASCII.
Кодови страници и пропуски
По-нататъшно развитие на технологиите и появата на GUI доведе до факта, че Американският институт по стандартизация е създал кодиране на ANSI. За руските потребители, особено с опит, версията му е известна като Windows 1251. За първи път в нея е използвана понятието "кодова страница". Именно с помощта на кодови страници, съдържащи символи на национални азбуки, различни от латински, беше установено „взаимно разбирателство“ между компютрите, използвани в различни страни.
Въпреки това, наличието на голям брой различни кодировки, използвани за един език, започна да предизвиква проблеми. Имаше така наречените кракозябри. Те са възникнали от несъответствие на оригиналната кодова страница, в която е създадена всяка информация, и кодовата страница, използвана по подразбиране на компютъра на крайния потребител.

Като пример могат да бъдат цитирани горепосочените кодировки на CP160 и KOI8-R на кирилица. Буквите в тях се различават по кодовите позиции и принципите на поставяне. В първия те бяха подредени по азбучен ред, а във втория - в произволно. Можете да си представите какво се случва пред очите на потребител, който се е опитал да отвори такъв текст, без да има необходимата кодова страница или ако е бил неправилно интерпретиран от компютъра.
Създайте Unicode
Разпространението на Интернет и свързаните с него технологии, като електронната поща, доведе до факта, че в крайна сметка ситуацията с изкривяването на текстове е престанала да отговаря на всеки. Водещи ИТ компании са създали Unicode Consortium ("Unicode Consortium"). Таблицата с символи, представена им през 1991 г. под името UTF-32, позволява да се съхранят повече от един милиард уникални знака. Това беше най-важната стъпка към декодиране на текстове.

Въпреки това, първата универсална таблица на Unicode UTF-32 символни кодове не е широко използвана. Основната причина беше излишното съхраняване на информация. Бързо беше изчислено, че за страните, в които латиница кодиран с новата универсална таблица, текстът ще заема четири пъти повече място, отколкото при използване на разширената ASCII таблица.
Unicode развитие
Следната таблица с символи на Unicode UTF-16 е решила този проблем. Кодирането в него се извършваше наполовина на битовете, но в същото време броят на възможните комбинации намаляваше. Вместо милиарди символи, това ви позволява да спестите само 65 536. Въпреки това, той беше толкова успешен, че този номер, според решението на Консорциума, беше определен като основно пространство за съхранение на знака на Unicode стандарта.
Въпреки този успех UTF-16 не отговаряше на всички, тъй като количеството на съхраняваната и предавана информация все още беше два пъти по-високо. Универсалното решение е UTF-8, таблица с Юникод символи с променлива дължина. Това може да се нарече пробив в тази област.

Така, с въвеждането на последните два стандарта, таблицата със символи на Unicode решава проблема с едно кодово пространство за всички използвани в момента шрифтове.
Unicode за руски език
Поради променливата дължина на кода, използван за показване на символи, латиницата се кодира в Unicode по същия начин, както в неговия ASCII предшественик, т.е. в един бит. За други азбуки картината може да изглежда различно. Например знаците на грузинската азбука се използват за кодиране на три байта, а знаците на кирилицата - две. Всичко това е възможно в рамките на използването на Unicode UTF-8 стандарта (символна таблица). Руският език или кирилицата заема 448 позиции в общото кодово пространство, разделено на пет блока.
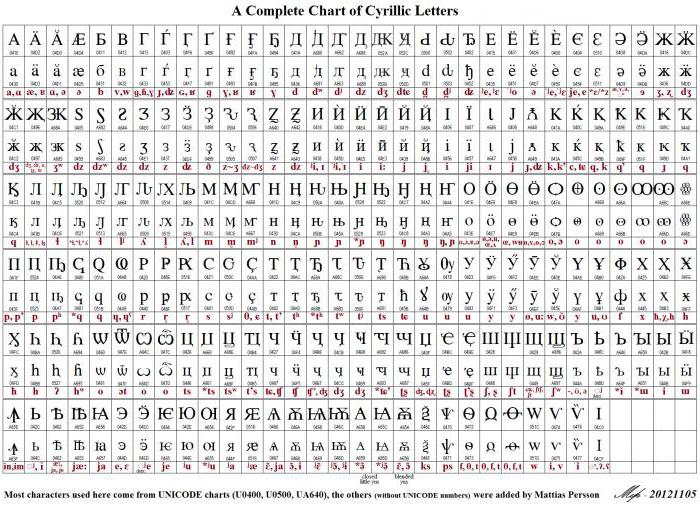
Тези пет блока включват основната кирилица и църковнославянската азбука, както и допълнителни букви на други езици, използващи кирилица. Редица позиции се разпределят за показване на старите форми на кирилица, докато 22 от общия брой остават свободни.
Текущата версия на Unicode
С решението на своята основна задача, която беше да се стандартизират шрифтове и да се създаде едно кодово пространство за тях, Консорциумът не спря работата си. Unicode непрекъснато се развива и развива. Последната актуална версия на този стандарт, 9.0, беше пусната през 2016 година. Той включва шест допълнителни азбуки и разширява списъка със стандартизирани емотикони.
Трябва да се отбележи, че за да се опростят научните изследвания, дори и така наречените мъртви езици. Те са получили това име, защото няма хора, за които да са роднини. Тази група включва и езици, които са стигнали до нашето време само под формата на писмени паметници.
По принцип всеки може да кандидатства за добавяне на символи към новата Unicode спецификация. Вярно е, че това ще трябва да запълни прилична сума от документи и да прекарва много време. Жив пример за това е историята на програмиста Теренс Еден. През 2013 г. той кандидатства за включване в спецификацията на символи, свързани с обозначаването на бутоните за управление на компютъра. В техническата документация те са използвани от средата на 70-те години на миналия век, но докато се появи спецификация 9.0, те не са били част от Unicode.
Таблица със символи
На всеки компютър, независимо от използваната операционна система, се използва таблица със символи на Unicode. Как да се използват тези таблици, къде да ги намерите и защо те могат да бъдат полезни на средния потребител?
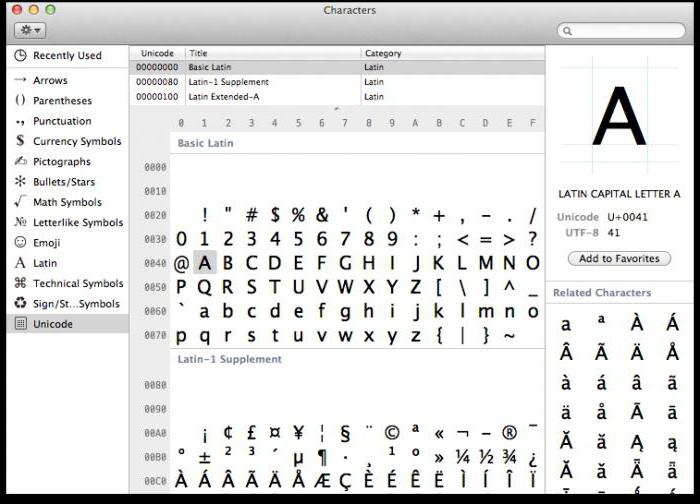
В Windows таблицата със символи се намира в менюто "Инструменти". В семейството на операционните системи Linux обикновено може да се намери в подраздела “Стандарт” и в MacOS в настройките на клавиатурата. Основната цел на тази таблица е да въвеждате символи в текстови документи, които не се намират на клавиатурата.
Заявлението за такива таблици може да се намери най-широко: от въвеждането на технически символи и икони на националните парични системи до писане на инструкции за практическото приложение на картите Таро.
В заключение
Unicode се използва навсякъде и навлиза в живота ни заедно с развитието на интернет и мобилните технологии. Благодарение на използването му, системата на междуетнически комуникации е значително опростена. Можем да кажем, че въвеждането на Unicode е индикативно, но напълно незабележимо от примера за използване на технологията за общото благо на цялото човечество.